
OPC UA: Datenarchitekturen als Wegbereiter zur Smart-Factory
August 15, 2021
15 min
Industrie 4.0
In diesem Beitrag geht es um das industrielle Kommunikationsprotokoll OPC Unified Architecture (im Folgenden OPC UA). OPC UA steht für Open Platform Communications Unified Architecture. Wie so häufig geht es auch bei diesem Kommunikationsprotokoll darum, Maschinendaten zu transportieren. Die OPC Foundation hat OPC UA entwickelt und organisiert die darauf aufbauenden Entwicklungen welche in den letzten Jahren rasant zugenommen haben. Das Vorgänger Kommunikationsprotokoll von OPC UA heißt OPC Data Access (OPC DA) und wird heute noch häufig im industriellen Bereich verwendet. Wo die Stärken von OPC UA sind, wofür Unified Architecture steht und weshalb man hiermit „interoperable Clients“ ermöglich kann soll in diesem Beitrag erklärt werden.
Wie funktioniert OPC UA?
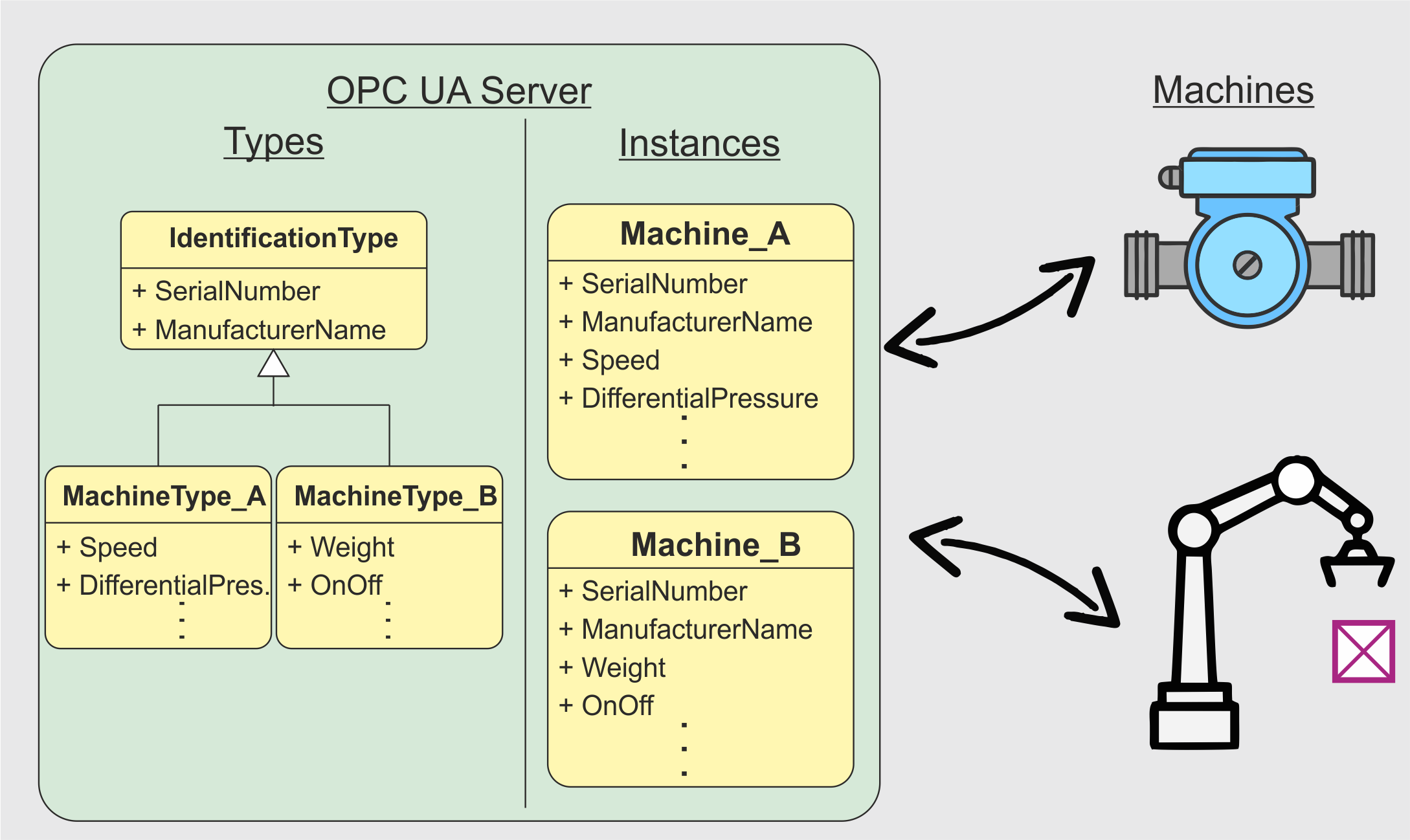
Ein OPC UA Server arbeitet mit den klassischen Methoden der Objektorientierung. Man kann in einem OPC UA Server Typen anlegen, die dann innerhalb des OPC UA Severs mehrfach instanziiert werden können (siehe Abbildung 1). In den Instanzen liegen dann die eigentlichen Datenpunkte, die mit den Maschinendaten verknüpft werden. Die Typen in einem OPC UA Server arbeiten, wie zuvor bereits beschrieben, nach den klassischen Methoden der Objektorientierung. Dies bedeutet, dass auch der Modellierungsansatz der „Vererbung“ genutzt werden kann. Was darunter zu verstehen ist wird in Abbildung 1 dargestellt. Es kann bspw. eine übergeordnete Klasse geben, die sich IdentificationType nennt. Dort sind generelle Datenpunkte wie die Seriennummer und der Name des Produktherstellers hinterlegt. Von dieser übergeordneten Klasse können dann verschiedene untergeordnete Klassen (in diesem Beispiel MachineType_A und MachineType_B) die Merkmale „vererbt“ bekommen. Zu erkennen ist dies daran, dass in den Typen der beiden Maschinen-Typen lediglich die Datenpunkte der spezifischen Maschinen hinterlegt sind (Drehzahl, Druck, Gewicht, An-Aus), in den Instanziierungen besitzen dann aber alle Maschinen darüber hinaus die Datenpunkte des IdentificationType "Seriennummer" und "Herstellername".
Bisher haben wir nur die Möglichkeiten der Instanziierung und Vererbung erläutert. Dies ist zwar ein mächtiges Werkzeug von OPC UA, jedoch noch nicht die Eigenschaft die den aktuellen Hype um OPC UA auslöst. OPC UA wird (bei korrekter Umsetzung) es ermöglichen, dass Client-Anwendungen sich automatisch mit OPC UA Servern verbinden können und die vorhandenen Datenstrukturen vom Server in die entsprechende Client-Anwendung integrieren. Ob eine Maschine dabei von Hersteller A oder Hersteller B zur Verfügung gestellt wird ist irrelevant. Dies versteht man unter der Begrifflichkeit „Interoperabilität“. Um diesen Use-Case verständlich zu erklären ist es hilfreich das ganze einmal so aufzuarbeiten, wie es nach bisherigem Wissenstand funktionieren würde.
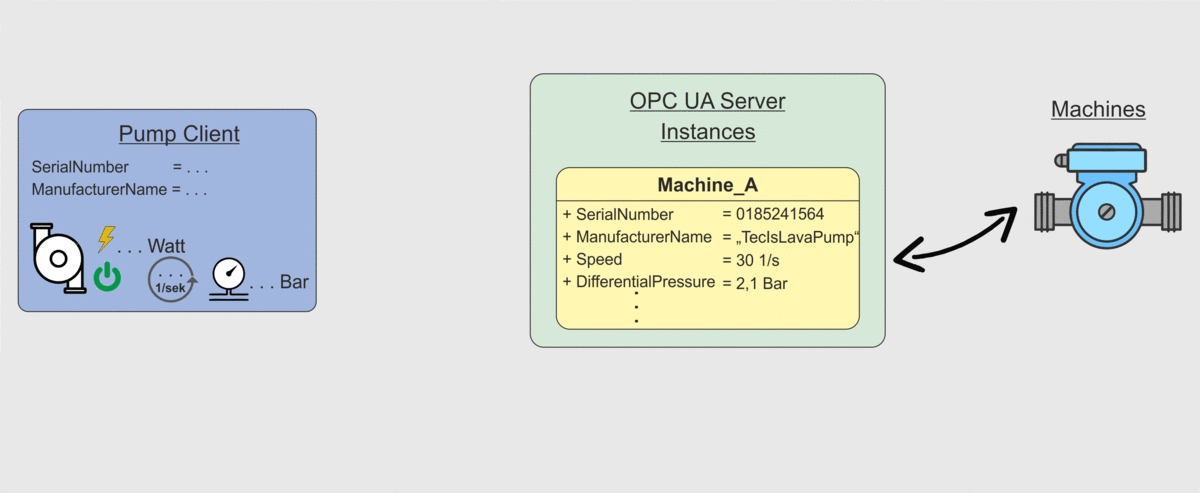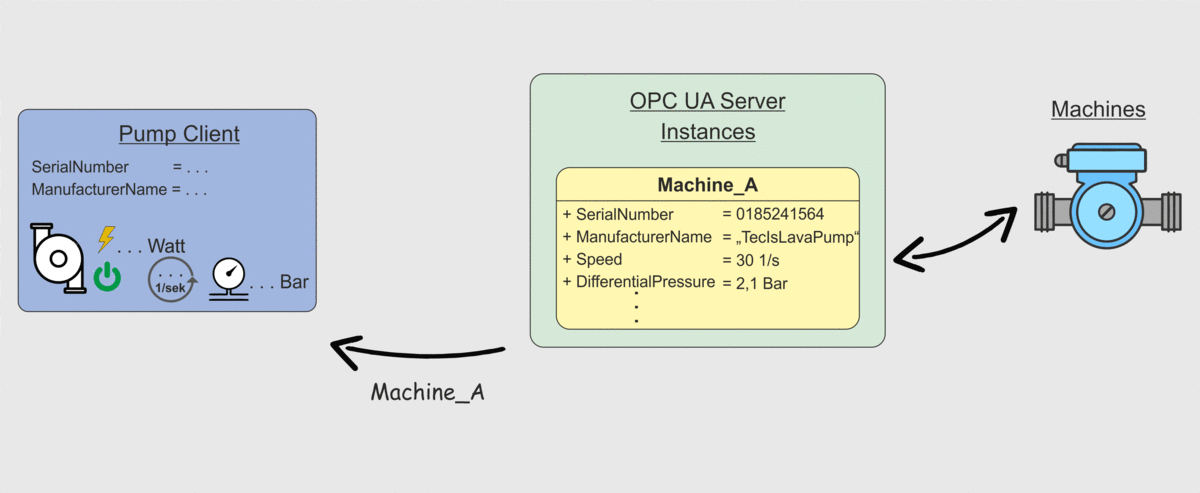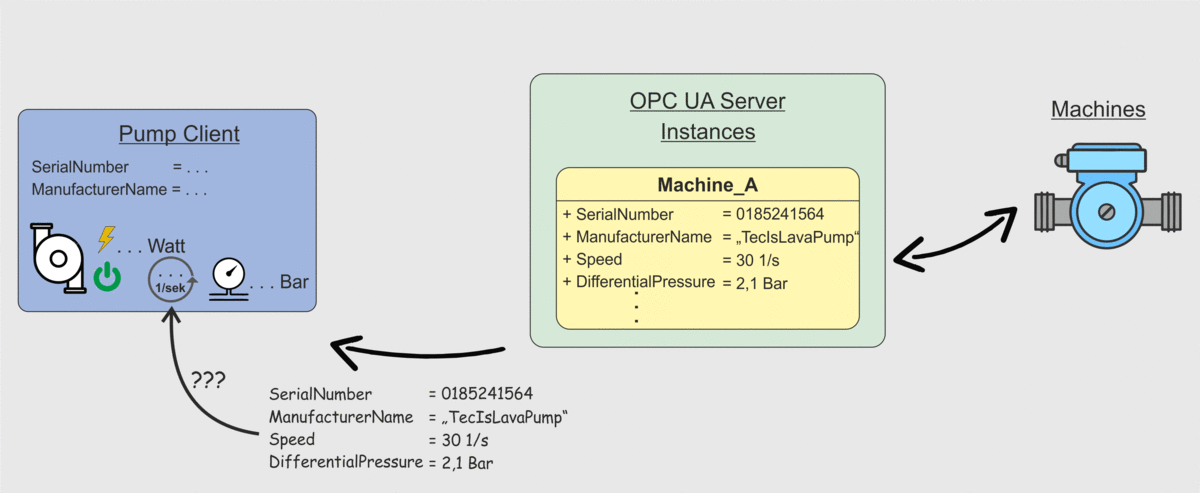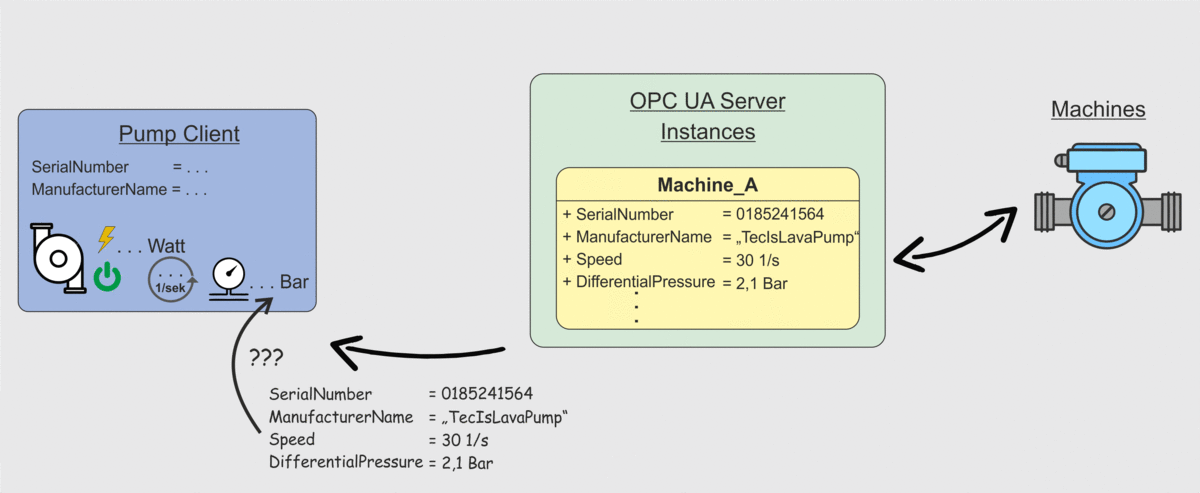
Ein Client kann beim Server nachfragen „Was hast du für Instanziierte Klassen?“ und „Welche Datenpunkte sind in diesen Klassen?“. Der Server übermittelt daraufhin dem OPC UA Client die entsprechenden Datenpunkte. Jedoch ist dies nicht hilfreich, wenn ein Client (wie in Abbildung 2 dargestellt) nicht weiß, was er mit einem Datenpunkt „Speed“ machen soll. Für einen Menschen ist es einfach eine Drehzahl zu erkennen, wenn der Datenpunkt „Speed“ heißt. Eine Maschine weiß das aber nicht. Es ist also notwendig dieses „Wissen“ auf irgendeine Art festzuhalten und maschinenlesbar zwischen Client und Server zu transportieren. Genau dies ist die Eigenschaft, weshalb OPC UA als der zukünftige defacto Standard der Industrie angesehen wird. Das „Wissen“, also die semantische Ausprägung im Datenmodell von OPC UA, wird in sogenannten OPC UA Companion Specifications festgehalten.
OPC UA Companion Specifications
Wie wird eine OPC UA Companion Specification entworfen?
Eine offizielle OPC UA Companion Specification kann nicht jeder für sich selbst definieren. Dies würde an der Idee, Client-Anwendungen zu ermöglichen die herstellerunabhängig Maschinen-Daten verarbeiten können, vorbei gehen und das Gegenteil bewirken. Wenn jeder Hersteller seine eigene semantische Ausprägung in Form einer OPC UA Companion Specification erstellt, hätte man wenig im Vergleich zu etablierten Kommunikationsprotokollen wie bspw. OPC DA gewonnen. Aber wie entsteht jetzt eine OPC UA Companion Specification? In der Regel funktioniert es so, dass nationale und internationale Verbände aus dem Maschinenbau (in Deutschland bspw. der VDMA) die einzelnen Maschinenhersteller (Pumpen, Robotertechnik, Kompressoren) an einen Tisch holen und zusammen die semantische Ausprägung erarbeiten. Der Verband reicht das ganze dann bei der OPC Foundation ein welche die Inhalte dann letztendlich absegnet und für alle Mitglieder der OPC Foundation zur Verfügung stellt. Neben den Inhalten koordiniert die OPC Foundation auch, dass nicht zu gleichen Maschinen unterschiedliche Companion Specifications entworfen werden. Wenn ein Verband mit Herstellern zusammen eine Companion Specification zum Thema „Küchenmaschinen“ erarbeitet, achtet die OPC Foundation darauf, dass nicht gleichzeitig auf der anderen Seite der Welt eine ähnliche Companion Specification entworfen wird. „Küchenmaschinen“ sind ein abstrakte Beispiel bei dem man nicht zwangsläufig an eine industrielle Kommunikationsschnittstelle denkt, aber es gibt hier eine OPC UA Companion Specification dazu.
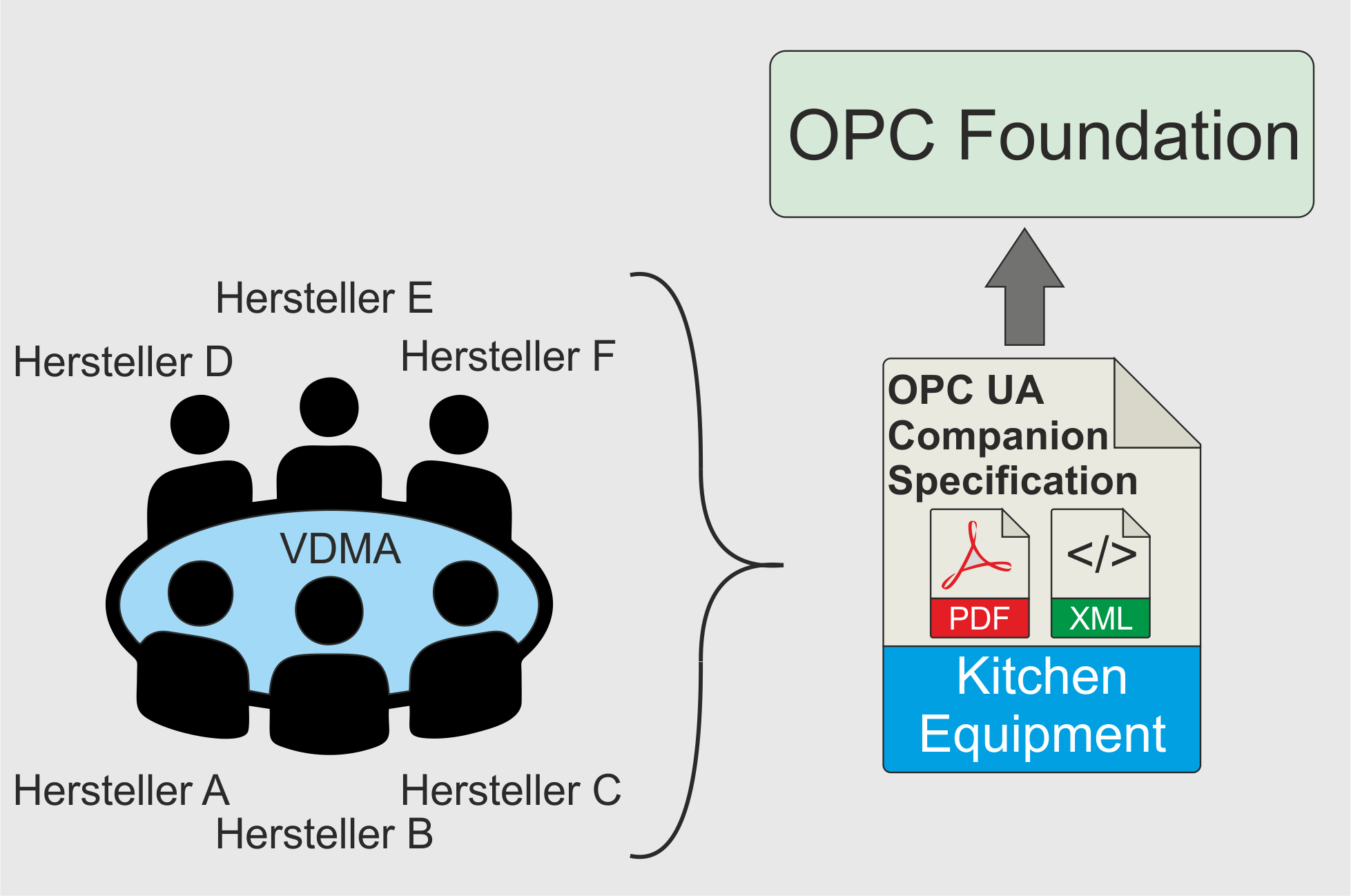
Woraus besteht eine OPC UA Companion Specification?
Die eigentliche OPC UA Companion Specification besteht hauptsächlich aus zwei Dateien:
- Die eine Datei ist eine Textdatei in der nach einem vorgegebenen Template die Inhalte der semantischen Ausprägung eingetragen werden. Die Textdatei kann als PDF nur von Mitgliedern runtergeladen werden (jeder, auch Privatpersonen, kann sich kostenfrei bei der OPC Foundation als Mitglied anmelden und dann die fertigen Dokumente einsehen). Aus dem Textdokument wird aber auch eine online Referenz erstellt welche für alle frei zugänglich ist. Beispiele sind Companion Specification für Pumpen und Vakuumpumpen oder die Companion Specification zu Küchenequipment.
- Die zweite Datei stellt die Inhalte aus der „menschenlesbaren“ Textdatei als maschinenlesbare XML-Datei zur Verfügung. Diese kann dann von OPC UA Servern genutzt werden um die Datenstruktur in den Server zu integrieren. Die XML Dateien werden von der OPC Foundation über GitHub laufend aktualisiert und frei zur Verfügung gestellt.
Client-Beispiel
Weiter oben in diesem Beitrag hatten wir in Abbildung 2 das Problem dargestellt, dass eine Client-Anwendung zwar die Datenpunkte von einem Server abrufen kann, die Client-Anwendung aber kein Wissen darüber besitzt was die einzelnen Datenpunkte bedeuten. Hier kommt nun die OPC UA Companion Specification ins Spiel. Client-Anwendungen können durch Berücksichtigung der OPC UA Companion Specification so entwickelt werden, dass ein Client weiß unter welchem Datenpunkt er welche Information erhält. Dieses Szenario ist in der Folgenden Abbildung dargestellt. Der Client ruft wie auch bereits in Abbildung 2 die Datenpunkte ab, weiß aber jetzt wie er die Datenpunkte zu interpretieren hat und wie diese in die Anwendungen integriert werden können. Eine händische Zuordnung ist also nicht mehr notwendig.
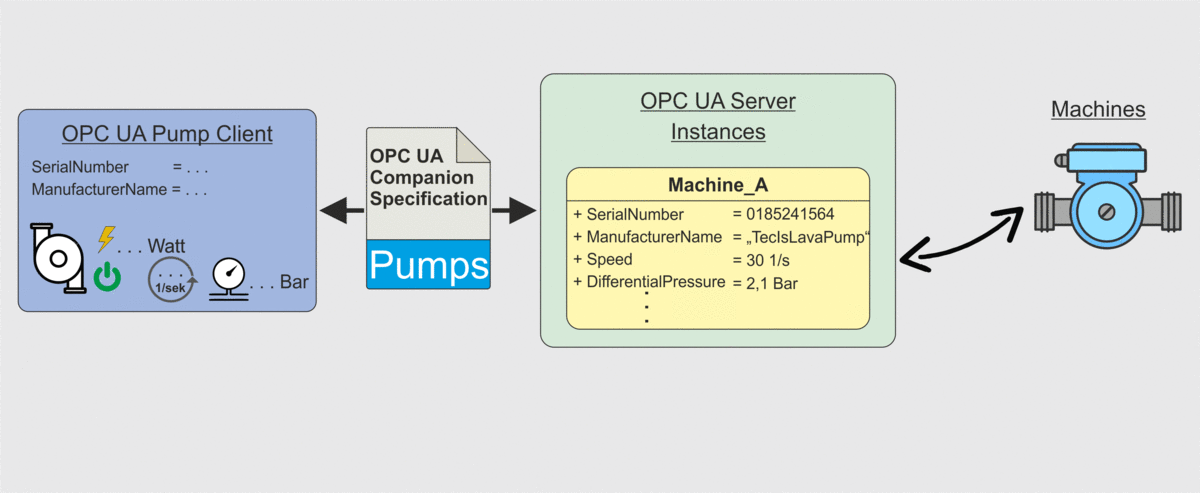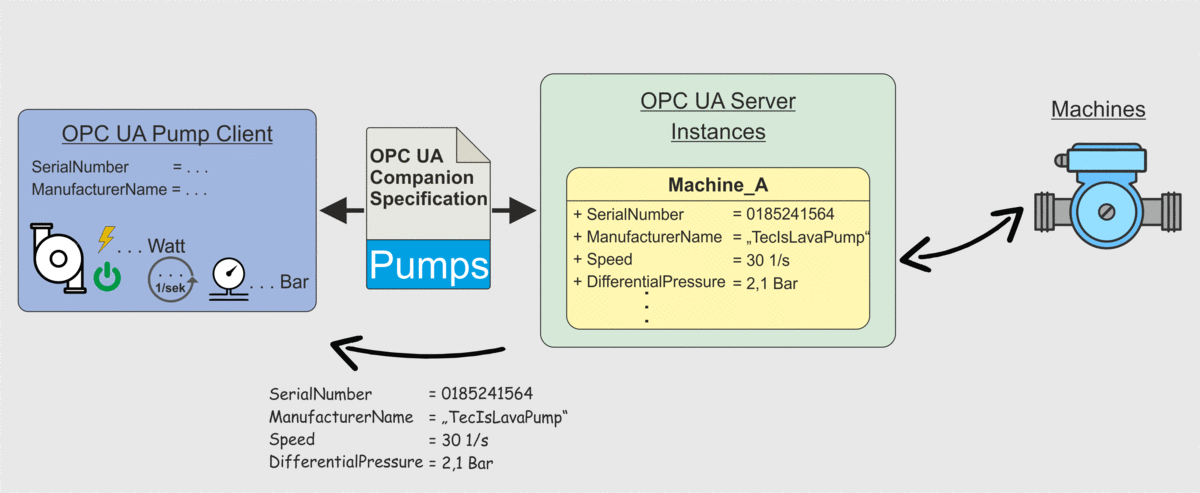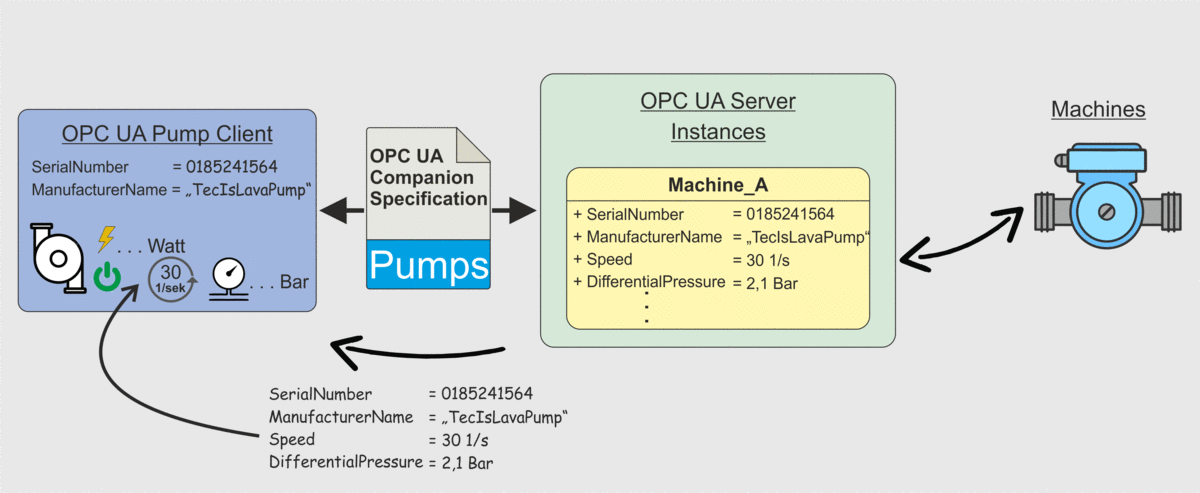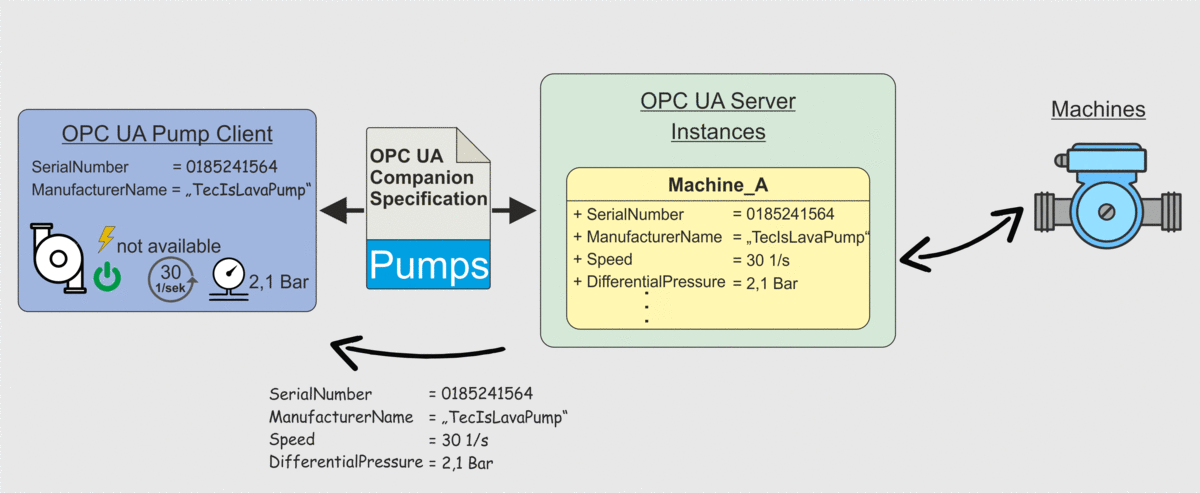
Zusammenfassung OPC UA
Das besondere an OPC UA ist also, dass man Maschinen semantisch beschreiben kann und basierend darauf Anwendungen entwickeln kann die das händische Engineering reduzieren. Es können durchaus Vergleiche zwischen der Technologie OPC UA und der Verwaltungsschale gezogen werden. Eine Verwaltungsschale hat auch das Ziel, die semantische Ausprägung von „Assets“ in so genannten Teilmodellen zu organisieren und die Informationen digital verfügbar zu machen. Die Verwaltungsschale ist heute aber noch sehr viel konzeptioneller zu interpretieren. Konkrete industrielle und nicht prototypische Umsetzungen gibt es Stand heute noch nicht. Davon abgesehen soll eine Verwaltungsschale ein Asset / eine Maschine über den gesamten Lebenszyklus begleiten und auch schon bei der Planung und der Bestellung als neutrales Informationsmodell im Hintergrund arbeiten. OPC UA konzentriert auf den realen Betrieb und den Datenaustausch zwischen live-Daten und Anwendungen. Wenn man einen weiteren Unterschied zwischen Teilmodellen und OPC UA Companion Specifications finden möchte, dann sieht es nach aktuellem Entwicklungsstand eher so aus, dass OPC UA Companion Specfications dazu dienen einzelne Komponenten / Maschinen zu beschreiben und Teilmodelle sich eher mit einzelnen Aspekten (bspw.: Identifikation, Dokumentation…) eines Assets befassen.
OPC UA aktuell & zukünftig
Die aktuelle Entwicklung von OPC UA besteht darin, dass in verschiedenen Fachgruppen die Companion Specifications modelliert und veröffentlicht werden. Es gibt neben kommerziellen OPC UA Stacks auch open-source Stacks die in verschiedenen Sprachen angeboten werden. Eine der wichtigsten Funktionalitäten der Stacks ist es, ob diese eine Funktion zum Einlesen der XML-Dateien von Companion Specifications besitzen. Es ist auch immer möglich einen Parser dafür händisch zu programmieren, jedoch hat sich in Umsetzungen gezeigt, dass dort viel Arbeit investiert werden muss. Client-Anwendungen gibt es bisher lediglich in alt-bekannter Form um die Datenstrukturen als Liste anzeigen zu lassen. Client-Anwendungen die spezifisch für einzelne Companion Specfications entwickelt wurden sind mir heute noch nicht bekannt.
OPC UA hat das große Ziel industrielle Kommunikationsschnittstellen interoperabel zu gestalten. Da hier natürlich einige Geschäftsmodelle „bedroht“ werden sind logischerweise nicht immer alle Parteien wunschlos glücklich mit der Detailierungstiefe die man in OPC UA umsetzen kann. Eine Möglichkeit wie Hersteller ihr Geschäftsmodell schützen können, liegt in der Entwicklung eigener Spezifikationen die auf allgemeinen Companion Specifications aufbauen. Niemand verbietet es, dass Hersteller ihr eigenes Informationsmodell erstellen und über die eigenen Firmenkanäle vertreiben. Die Architektur könnte dann beispielhaft wie in Abbildung 5 aussehen.

Die Küchenmaschinen basieren hier auf der öffentlichen, von der OPC Foundation bereitgestellten, Companion Specifications für Küchenequipment. Der Hersteller hat aber noch eigene Informationen hinzugefügt und kann somit das eigentliche Informationsmodell freier gestalten. Interoperable Client-Anwendungen können dann „nur“ das Informationsmodell der offiziellen OPC UA Companion Specification erkennen und eben nicht die Herstellerspezifischen Informationen.
In der Abbildung 5 sind noch zwei Spezifikationen zu erkennen, die bis hierhin nicht thematisiert wurden. OPC UA Device Identification und OPC UA for Machinery. Diese beiden Spezifikationen beschäftigen sich mit allgemeinen Themen wie „Identifikation von Maschinen“ und „Unter welchem Datenpunkt in OPC UA sollen Maschineninstanzen organisiert werden?“. Hier werden sehr allgemeine Merkmale wie Seriennummer und Herstellername definiert oder vorgeschrieben wo Maschineninstanzen für OPC UA Clients auffindbar sein sollen. Diese Entwicklungen werden nicht von Maschinenherstellern beeinflusst, sondern von der OPC Foundation bzw. Maschinen-Verbänden vorangetrieben. Auch wenn die Verbände versuchen die Entwicklungen der OPC UA Companion Specifications zu organisieren, gestaltet es sich schwierig alle nach dem gleichen Schema zu erstellen. Viele OPC UA Companion Specifications haben dann eben doch ihren eigenen „Slang“. Es wird also zukünftig immer noch eine Herausforderung sein einen einzelnen Client zu entwickeln, der alle Maschinen auf die gleiche Art und Weise auslesen wird. Damit aber wenigstens die sehr allgemeinen Merkmale wie eben Seriennummer und Herstellername in den OPC UA Companion Specifications gleich aussehen, werden diese Entwicklungen von Verbänden geleitet. Die Fachgruppen für die jeweiligen OPC UA Companion Specifications der Maschinen werden dann dazu „animiert“ diese zu berücksichtigen und zu unterstützen. OPC UA wird also auch nicht alle Probleme lösen. Ein Client für eine Pumpe wird anders programmiert werden müssen als ein Client für einen Roboterarm. Maschinen unter sich sollten aber in den Grundfunktionen zukünftig gleich unterstützt werden.
In dem Beitrag zu MQTT haben wir erwähnt, dass MQTT leichtgewichtig ist und sich daher vor allem für „Bastler-Projekte“ eignet. OPC UA ist hier ein Stück weit das Pendant. OPC UA hat eine anspruchsvolle Architektur und bis man einen effektiven Nutzen aus OPC UA ziehen kann ist es ein weiter Weg. Bei korrekter Umsetzung werden aber industrielle Anwendungen der Zukunft damit sehr viel effizienter betrieben werden können.
Auch zu OPC UA ist ein Implementierungsbeispiel in Arbeit, welches zeigen soll wie man eine eigene kleine OPC UA Companion Specification entwickeln, diese in einen lauffähigen-Server implementiert werden kann und wie ein nutzvoller OPC UA Client dazu aufgesetzt werden kann.



